DP-203 Exam
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.

You need to alter the table to meet the following requirements:
✑ Ensure that users can identify the current manager of employees.
✑ Support creating an employee reporting hierarchy for your entire company.
✑ Provide fast lookup of the managers' attributes such as name and job title.
Which column should you add to the table?
[ManagerEmployeeID] [smallint] NULL
[ManagerEmployeeKey] [smallint] NULL
[ManagerEmployeeKey] [int] NULL
[ManagerName] varchar NULL
You have an Azure Synapse workspace named MyWorkspace that contains an Apache Spark database named mytestdb.
You run the following command in an Azure Synapse Analytics Spark pool in MyWorkspace.
CREATE TABLE mytestdb.myParquetTable(
EmployeeID int,
EmployeeName string,
EmployeeStartDate date)
USING Parquet -
You then use Spark to insert a row into mytestdb.myParquetTable. The row contains the following data.

One minute later, you execute the following query from a serverless SQL pool in MyWorkspace.
SELECT EmployeeID -
FROM mytestdb.dbo.myParquetTable
WHERE EmployeeName = 'Alice';
What will be returned by the query?
24
an error
a null value
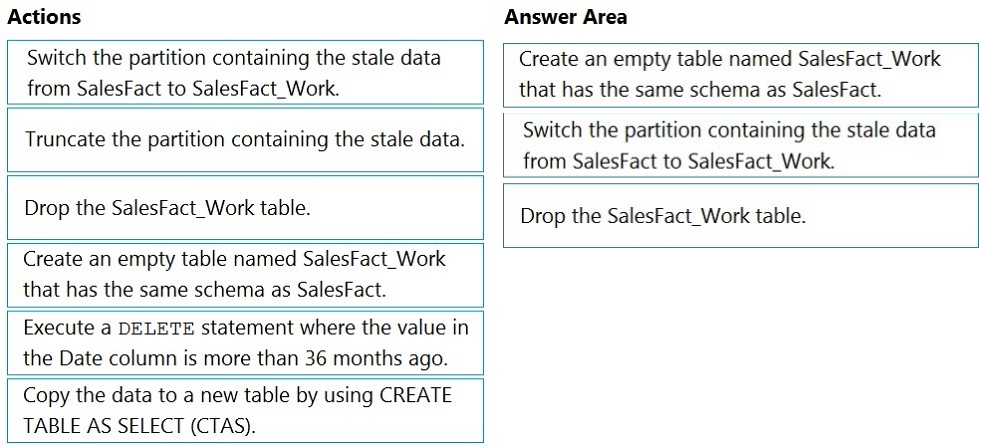
DRAG DROP -
You have a table named SalesFact in an enterprise data warehouse in Azure Synapse Analytics. SalesFact contains sales data from the past 36 months and has the following characteristics:
✑ Is partitioned by month
✑ Contains one billion rows
✑ Has clustered columnstore index
At the beginning of each month, you need to remove data from SalesFact that is older than 36 months as quickly as possible.
Which three actions should you perform in sequence in a stored procedure? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.
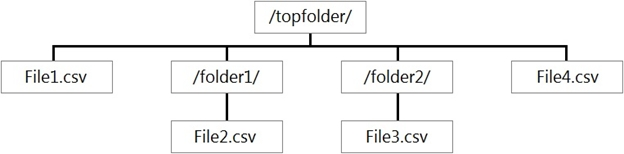
You create an external table named ExtTable that has LOCATION='/topfolder/'.
When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
File2.csv and File3.csv only
File1.csv and File4.csv only
File1.csv, File2.csv, File3.csv, and File4.csv
File1.csv only
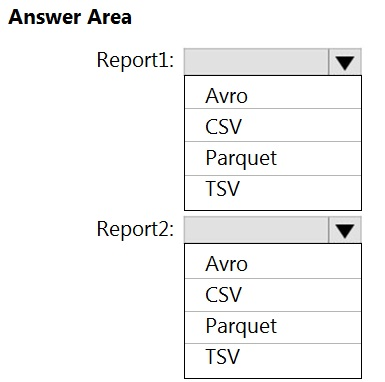
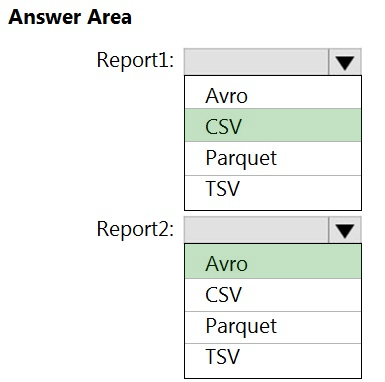
HOTSPOT -
You are planning the deployment of Azure Data Lake Storage Gen2.
You have the following two reports that will access the data lake:
✑ Report1: Reads three columns from a file that contains 50 columns.
✑ Report2: Queries a single record based on a timestamp.
You need to recommend in which format to store the data in the data lake to support the reports. The solution must minimize read times.
What should you recommend for each report? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Unlock All Questions
You are viewing the free preview. Purchase a plan to access all questions, answers, and detailed explanations.